(电子发烧友网报道 文/章鹰)2025年6月26日至27日,“2025高通汽车技术与合作峰会”在苏州举行,阿里云副总裁徐栋带来通义大模型在发展方向的最新思考,以及汽车领域的端云侧落地的方案。
通义系列模型衍生数量超Llama,三大方向形成
阿里巴巴的“AI大模型” 通义千问大模型最初于2023年4月7日开始邀请测试,并在2023年4月11日的阿里云峰会上正式揭晓。徐栋在会议上提及,阿里巴巴在AI大模型上有两个品牌:一个是通义千问VL,另外一个是通义万相,Qwenz的知名度更高一些。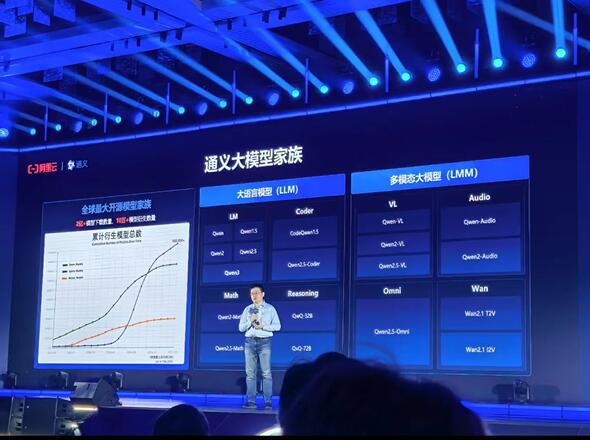
阿里巴巴除了大语言模型外,还有多模态大模型,徐栋分析说,当下三大发展方向分别是:1、耳聪目明,能说会画;2、思考与探索,让模型学会慢思考,而且慢思考的过程中学会使用工具,慢思考执行复杂任务,抑制幻觉。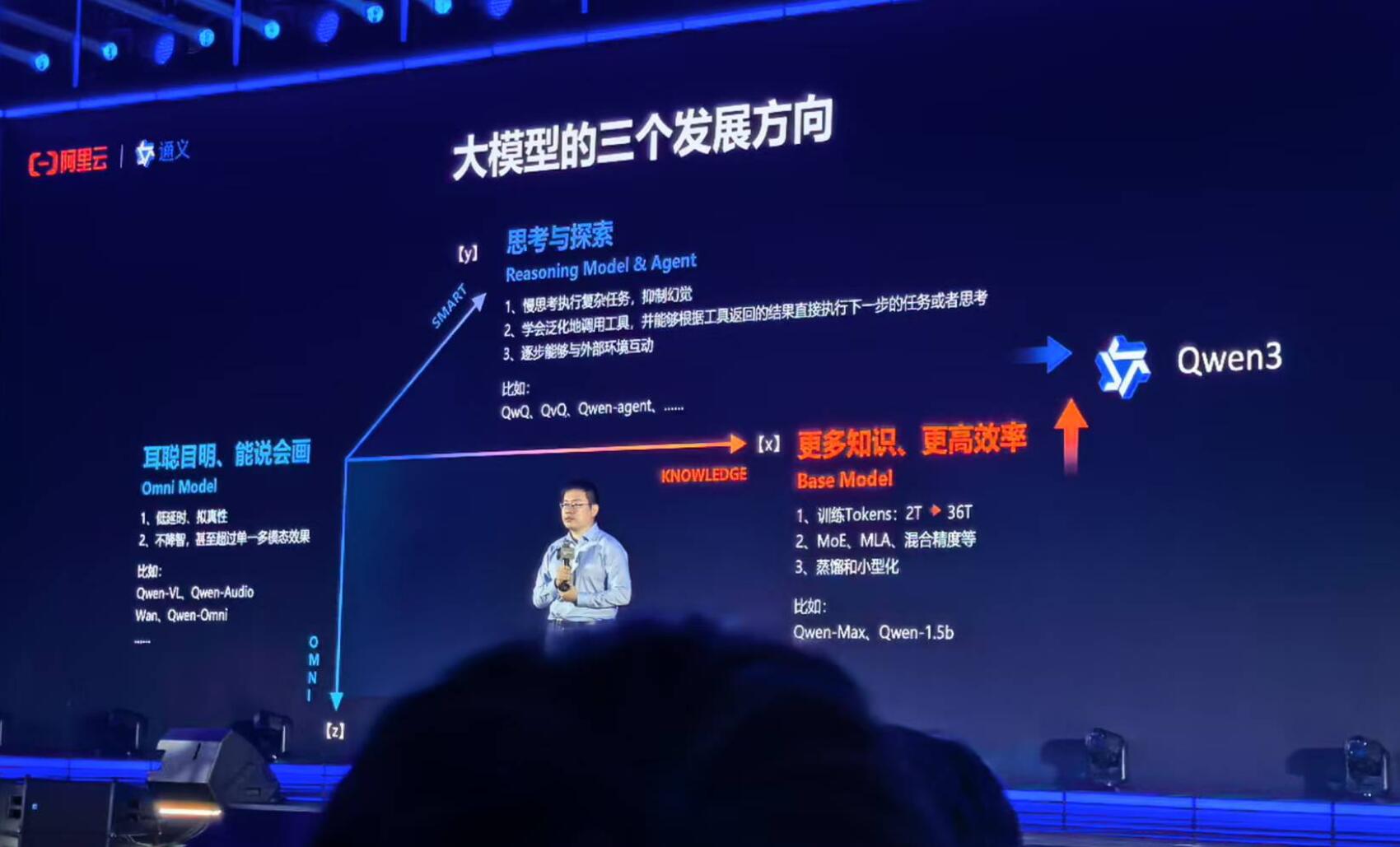
3、更多知识,更高效率。我们会沿着预训练的方向,加大数据,提高模型的架构上的一些效率,我们也会用更多的MoE 包括混合精度的方式,然后每个Token背后所对应的钱,成本包括了芯片和电费能够达到最低,我们的这一代的模型的训练的数据量已经到了36T的Token,相比我们第一代模型已经涨了差不多18倍左右。
阿里巴巴开发的AI大模型具备多模态、参数细分和快速迭代三大特点。
徐栋指出:“阿里巴巴推出的AI大模型,参数切分得很细,从0.5亿参数、20亿、70亿到2000亿参数的MoE模型都有,我们自己做的实验,14B以下的模型都有可能和高通芯片去做适配,未来有机会上载到汽车上。”
他特别强调,阿里巴巴在AI大模型方面的核心竞争力是迭代速度快。2023年,阿里推出AI大模型,一年更新四次。现在更新速度加快,基本上1个月更新2-3个模型。值得关注的是,阿里巴巴的通义系统模型已经是全球范围内开源衍生模型数量最多的一个平台,在2024年10月已经超过美国Llama的衍
生模型数量,夯实了我们的核心竞争力。
比如2023年8月,阿里Qwen-7B诞生:首个开源的70亿参数模型,支持8K上下文;2023年9月,Qwen-14B上市,扩展到140亿和720亿参数,性能逼近GPT-3.5;2024年2月,Qwen1.5系列推出,包括0.5B至72B多个尺寸,全面支持32K上下文,取消商业限制;2024年9月,Qwen2.5系列推出,强化知识、代码和数学能力,推出专业优化模型如Qwen2.5-Coder和Qwen2.5-Math。
AI座舱渗透率上升,大模型上车加速
“自动驾驶主要是基于视觉AI的能力,整个座舱有没有可能就是一个超大的智能体,座舱里面有很多屏幕、摄像头,随着模型能力快速成长,汽车将有机会率先成为有自我意识、自我迭代、快速决策的智能体。” 阿里云副总裁徐栋表示。
徐栋说,当下的技术能力,端侧、云端,最重要的就是保护个人隐私。如何在确保隐私的前提下,把不同设备连接起来,专项的模型需要重点考虑。当下,汽车上高端芯片的算力得以提升,模型的能力越来越强。
2025年4月29日,阿里巴巴推出了Qwen3模型,Qwen3系列模型包含2个混合专家(MoE)模型和6个稠密(Dense)模型,覆盖6亿、17亿、40亿、80亿、140亿、320亿、300亿、2350亿全尺寸参数规模。2025年中国大模型的发展主脉络之一仍是,提升精度并降低算力成本。小尺寸模型可以在满足基本需求的情况下节省算力成本,大尺寸模型则适合追求极限性能的用户。
徐栋认为,在云端,面向导航出行、数字娱乐、车生活场景提供丰富的智能体应用,采用Dense-32B+或MoE-200B+以上模型,具备深度思考能力,可以对复杂的问题进行推理。端侧的多模态大模型,主要对座舱意图进行多模态识别,强化传统“车控、导航、多媒体域”的识别。端云大模型协同,才能推动汽车智能座舱迈向AI座舱。
据行业专家介绍,7B-14B参数轻量级模型适合于本地化部署,如DeepSeek蒸馏小模型,在车端运行流畅,提供低延迟响应。采用混合专家(MoE)架构,如盘古Pro MoE(72B参数),在昇腾芯片优化下实现高效推理,适合智能驾驶任务。最新消息,阿里巴巴已经和宝马公司官宣合作,基于阿里通义AI大模型,联合开发AI引擎,将应用于中国市场的宝马新世代系列车型。
来源:电子发烧友
